
There’s a definite pride in owning something that you put together yourself. It also lowers your expectations of perfection. Eventually you need to stop tinkering and get to business. If you buy table from the furniture stop then that thing better come in pristine condition. But if you build your own table, all the imperfections become part of the table’s journey. Today we will examine the overall components of our Kubernetes cluster and why it looks different than an idealized illustration. Please excuse the mess.

A Word About Redundancy
An aspect of managing enterprise technology that can drive you mad is redundancy. It’s a wonderful dream to have a failover for everything. Your file goes missing – here’s the backup. Your drive drops dead – it has a twin. But the entire server can go kaput or you could lose power to the entire building or a tornado could erase the entire city. Redundancy can be managed for all these scenarios, but you need to pick the appropriate place for you within the constraints unique to your organization.
For us, we focus on backups for irreplaceable data. Anything that can’t be remade is backed up locally then replicated out to a remote location. Hardware failures are managed by either having spare parts on hand or knowing where to get them quickly. In other words, we are accepting that downtimes may occur and it’s the trade-off for not making an extreme investment into redundancy at every level. It also keeps our infrastructure on premise, which maximizes flexibility and serviceability.
I’m not going to talk a lot about redundancy with Kubernetes. This is absolutely a strength of Kubernetes. But it’s not the reason we’re using Kubernetes in our infrastructure. We are running testing sites alone and there is no expectation for perfect uptime. In a production environment you would have exactly the opposite expectation. And for that we leverage cloud hosting providers.
Getting to Know the Team
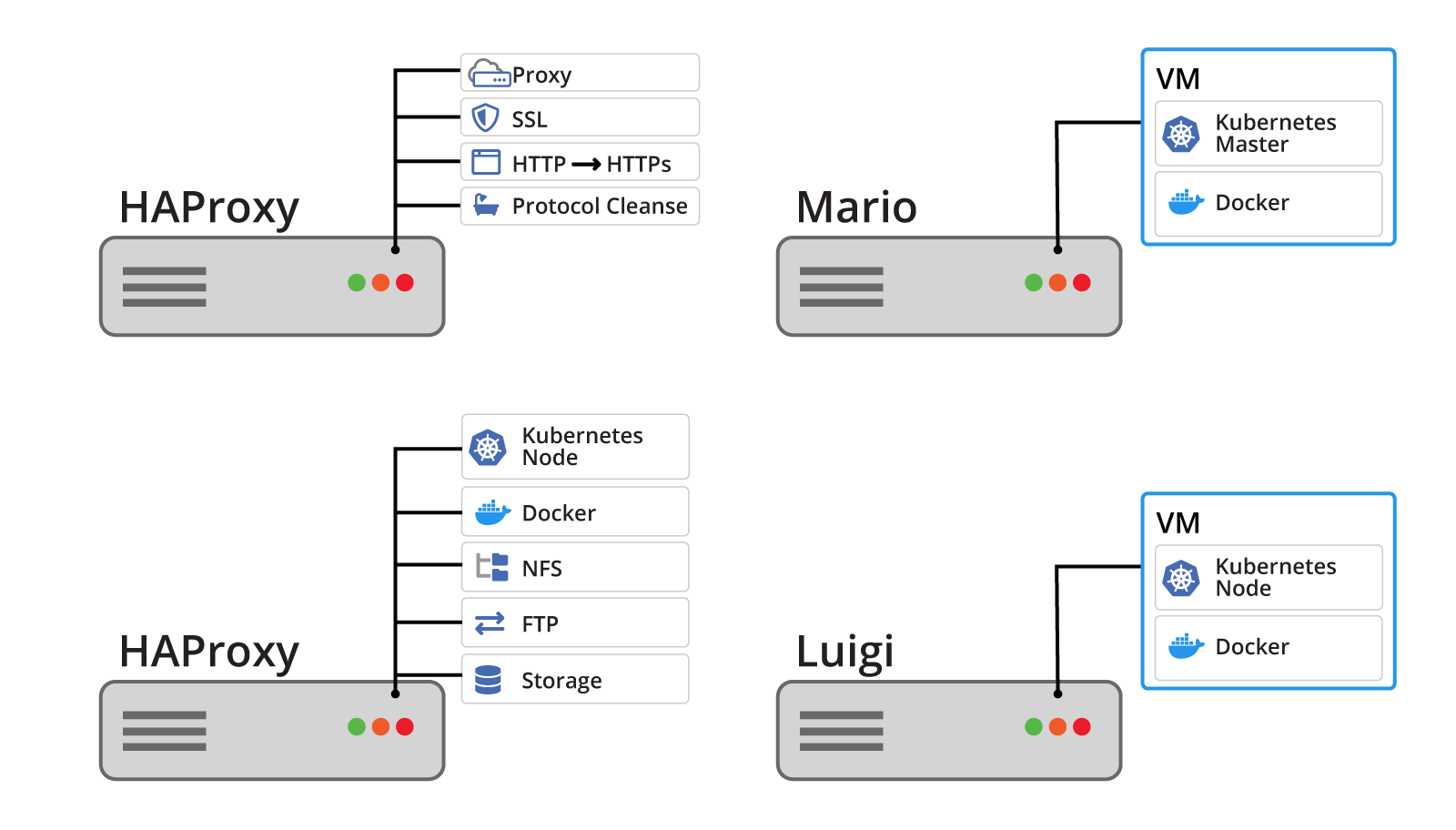
We have two large virtual machine servers: Mario and Luigi. They host many virtual machines for many purposes. For the Kubernetes cluster there is a virtual machine on Mario which serves as the Kubernetes master node. Luigi has a virtual machine as a Kubernetes node. Each virtual machine runs Docker as the container runtime. Normally the master node is reserved for the management of the cluster, but we configured it to accept workloads as well.
An independent server runs HAProxy for both the Kubernetes cluster and other services. HAProxy handles all SSL certificates, all non-secure to secure redirects, and provides protocol cleansing for a few legacy systems. HAProxy is such a fundamental part of our overall network infrastructure and running the service outside of the virtual machine environment helps with uptime.
Another server provides persistent network storage for applications both inside and outside of the Kubernetes cluster. This server is named Stash. Although Stash is just network-attached storage, it presents the storage via the NFS and FTP protocols. To simplify the ongoing management of those services, Stash is set up as a Kubernetes node and is attached to the main cluster. The node is configured to only run workloads specifically assigned to Stash.
The Team Dynamics
The master node on Mario hosts the Kubernetes API. This API is where all configuration changes are made within the cluster. These changes are applied by the master node to the other nodes within the cluster. This results in Docker containers being run on Mario, Luigi, and Stash.
Docker containers are frequently destroyed as part of their normal lifecycle. This also causes data within the container to be lost. Any data that needs to be persisted is stored on Stash and is mounted into a container via an NFS volume mount. The mounted volume appears as a normal folder to the application running in the container.
All web traffic goes through HAProxy on its way to the appropriate application. This compliments how Kubernetes exposes application endpoints. It prefers to use ports in a non-standard range. HAProxy can standardize this into a scheme which end users will more easily understand. HAProxy also centralizes your SSL certificates. This mean you do not need to configure and manage SSL certificates and settings for each individual application.
Next Steps
In the next post we will begin talking about each server in detail, including how each was initially set up.
Additional Resources
HAProxy is an amazing open source project that you should learn more about. We enjoy naming our servers with pet names because we only have a few. If you have many, I would recommend other schemes.